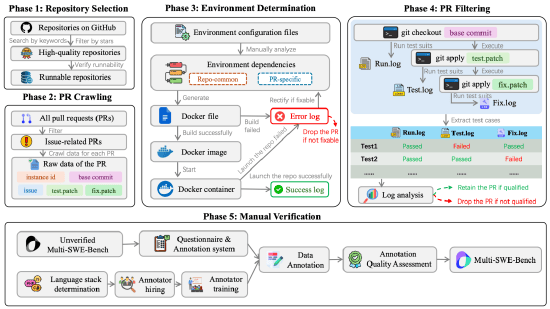
仟茂科技讯 4月10日下午消息,字节跳动豆包大模型团队开源首个多语言类 SWE 数据集“Multi-SWE-bench”,可用于评估和提升大模型“自动修 Bug”能力。在SWE-bench基础上,Multi-SWE-bench首次覆盖Python之外的7种主流编程语言,是真正面向栈工程”的评测基准。 豆包大模型团队希望,Multi-SWE-bench 能作为大模型在多种主流编程语言与真实代码环境中的系统性评测基准,推动自动编程能力向更实用、更工程化的方向发展。相比于以往聚焦 Python 的单语言任务,Multi-SWE-bench 更贴近现实中的多语言开发场景,也更能反映当前模型在“自动化软件工程”方向上的实际能力边界。(张奥) 责任编辑:何俊熹 (责任编辑:郭健东 )
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com |