|
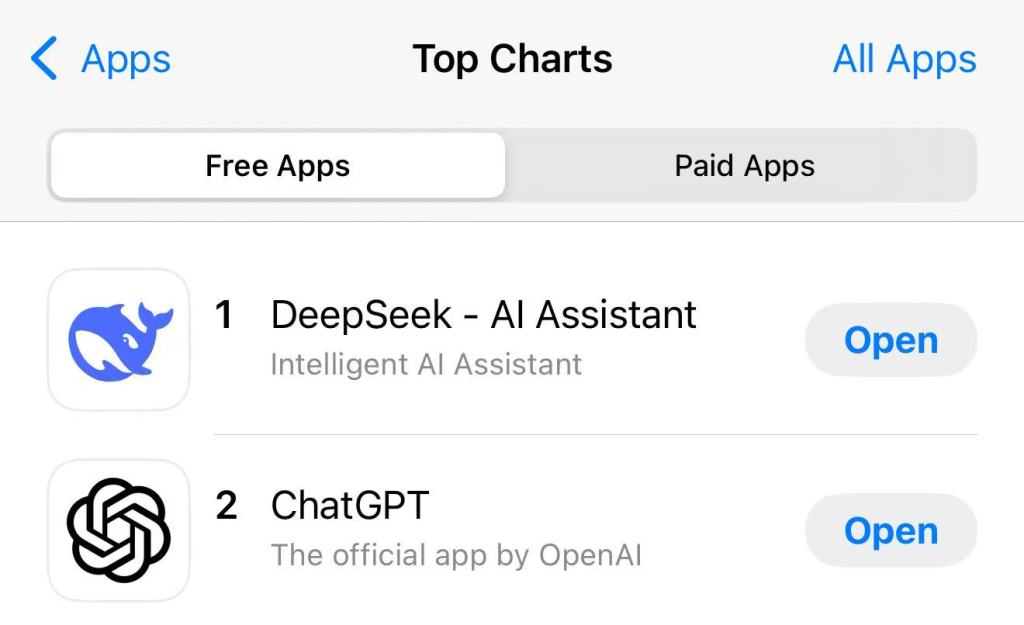
每经编辑 毕陆名 1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。
据广州日报报道,“DeepSeek爆火的原因主要可以归结为两点:性能和成本。”萨摩耶云科技集团首席经济学家郑磊告诉记者。DeepSeek解释称,R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。这种卓越的性能不仅吸引了科技界的广泛关注,也让投资界看到了其巨大的商业潜力。 更为关注的是,DeepSeek R1真正与众不同之处在于它的成本——或者说成本很低。DeepSeek的R1的预训练费用只有557.6万美元,仅是OpenAI GPT-4o模型训练成本的不到十分之一。同时,DeepSeek公布了API的定价,每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。这个收费大约是OpenAI o1运行成本的三十分之一,也因此,DeepSeek被称为AI界的“拼多多”。 “DeepSeek以较低的成本实现了高性能的AI模型,这使得其在市场竞争中具备了显著的优势,这种成本效益比无疑会吸引大量企业和个人用户选择其产品和服务。”北京社科院副研究员王鹏表示。 郑磊直言,DeepSeek对硬件市场产生了重大影响,因为它可能会降低人工智能模型的硬件成本,从而推动人工智能技术的发展。 另据媒体报道,为了训练模型,幻方量化在美国芯片出口限制之前获得了超过1万块英伟达GPU,尽管有说法称DeepSeek大约有5万颗H100芯片,但尚未得到公司官方证实。 早在去年12月,该公司推出的DeepSeek-V3通过优化模型架构和基础设施等方式,展现了极致性价比。从该团队正式发布的技术报告来看,包括预训练、上下文长度外推和后训练在内,DeepSeek-V3完整训练只需2.788M H800 GPU小时,其训练成本仅为557万美元,但该模型实现了与GPT-4o和Claude Sonnet 3.5(来自美国人工智能企业Anthropic)等顶尖模型相媲美的性能。 当时著名人工智能科学家卡帕西(Andrej Karpathy)就发文表示,这种级别的能力通常需要接近16000颗GPU的集群,而目前市场上的集群规模更是达到了10万颗GPU左右。 
图片来源:视觉中国 |